library(tidyverse)
data("germeval_train", package = "pradadata")
data("germeval_test", package = "pradadata")germeval10-wordvec-rf
textmining
datawrangling
germeval
prediction
tidymodels
string
Aufgabe
Erstellen Sie ein prädiktives Modell für Textdaten. Nutzen Sie deutsche Word-Vektoren für das Feature-Engineering.
Nutzen Sie die GermEval-2018-Daten.
Die Daten sind unter CC-BY-4.0 lizensiert. Author: Wiegand, Michael (Spoken Language Systems, Saarland University (2010-2018), Leibniz Institute for the German Language (since 2019)),
Die Daten sind auch über das R-Paket PradaData zu beziehen.
Die AV lautet c1. Die (einzige) UV lautet: text.
Hinweise:
- Orientieren Sie sich im Übrigen an den allgemeinen Hinweisen des Datenwerks.
- Nutzen Sie Tidymodels.
- Nutzen Sie Wikipedia2Vec als Grundlage für die Wordembeddings in deutscher Sprache. Laden Sie die Daten herunter (Achtung: ca. 2.8 GB).
Lösung
d_train <-
germeval_train |>
select(id, c1, text)library(tictoc)
library(tidymodels)
library(syuzhet)
library(beepr)
library(textrecipes)Eine Vorlage für ein Tidymodels-Pipeline findet sich hier.
Deutsche Textvektoren importieren
tic()
wiki_de_embeds <- arrow::read_feather(
file = "/Users/sebastiansaueruser/datasets/word-embeddings/wikipedia2vec/part-0.arrow")
toc()0.743 sec elapsednames(wiki_de_embeds)[1] <- "word"
wiki <- as_tibble(wiki_de_embeds)Workflow
# model:
mod1 <-
rand_forest(mode = "classification",
mtry = tune())
# recipe:
rec1 <-
recipe(c1 ~ ., data = d_train) |>
update_role(id, new_role = "id") |>
#update_role(c2, new_role = "ignore") |>
step_tokenize(text) %>%
step_stopwords(text, language = "de", stopword_source = "snowball") |>
step_word_embeddings(text,
embeddings = wiki,
aggregation = "mean")
# workflow:
wf1 <-
workflow() %>%
add_model(mod1) %>%
add_recipe(rec1)Preppen/Baken
tic()
rec1_prepped <- prep(rec1)
toc()68.465 sec elapsedd_train_baked <-
bake(rec1_prepped, new_data = NULL)
head(d_train_baked)# A tibble: 6 × 102
id c1 wordembed_text_V2 wordembed_text_V3 wordembed_text_V4
<int> <fct> <dbl> <dbl> <dbl>
1 1 OTHER -0.0648 -0.0664 0.0242
2 2 OTHER -0.207 -0.0102 -0.118
3 3 OTHER -0.246 -0.110 -0.195
4 4 OTHER -0.0139 -0.241 -0.135
5 5 OFFENSE -0.0803 -0.164 -0.160
6 6 OTHER -0.195 -0.00456 -0.132
# ℹ 97 more variables: wordembed_text_V5 <dbl>, wordembed_text_V6 <dbl>,
# wordembed_text_V7 <dbl>, wordembed_text_V8 <dbl>, wordembed_text_V9 <dbl>,
# wordembed_text_V10 <dbl>, wordembed_text_V11 <dbl>,
# wordembed_text_V12 <dbl>, wordembed_text_V13 <dbl>,
# wordembed_text_V14 <dbl>, wordembed_text_V15 <dbl>,
# wordembed_text_V16 <dbl>, wordembed_text_V17 <dbl>,
# wordembed_text_V18 <dbl>, wordembed_text_V19 <dbl>, …Tuninig/Fitting
tic()
wf_fit <-
wf1 %>%
tune_grid(
grid = 5,
resamples = vfold_cv(strata = c1,
v = 5,
data = d_train),
control = control_grid(save_pred = TRUE,
verbose = TRUE,
save_workflow = FALSE))
toc()
beep()Oder das schon in grauer Vorzeit berechnete Objekt importieren:
wf_fit <- read_rds("/Users/sebastiansaueruser/github-repos/rexams-exercises/objects/germeval10-wordvec-rf.rds")Plot performance
autoplot(wf_fit)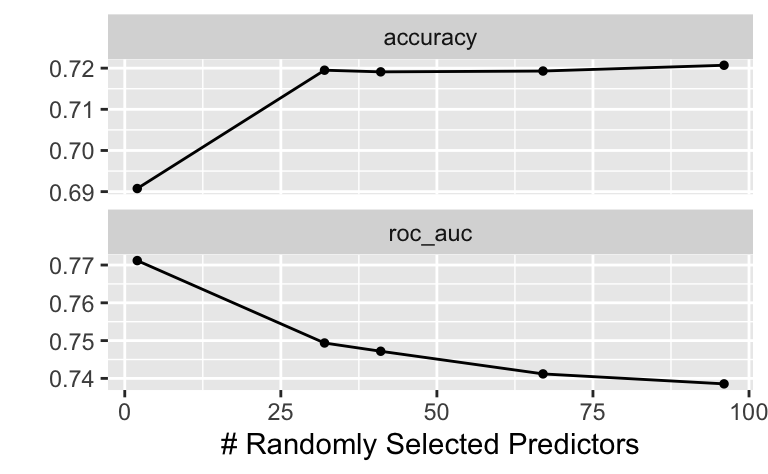
show_best(wf_fit)# A tibble: 5 × 7
mtry .metric .estimator mean n std_err .config
<int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 2 roc_auc binary 0.771 5 0.00846 Preprocessor1_Model3
2 32 roc_auc binary 0.749 5 0.00878 Preprocessor1_Model4
3 41 roc_auc binary 0.747 5 0.00859 Preprocessor1_Model2
4 67 roc_auc binary 0.741 5 0.00952 Preprocessor1_Model1
5 96 roc_auc binary 0.739 5 0.00883 Preprocessor1_Model5Finalisieren
best_params <- select_best(wf_fit)
tic()
wf_finalized <- finalize_workflow(wf1, best_params)
lastfit1 <- fit(wf_finalized, data = d_train)
toc()21.916 sec elapsedTest-Set-Güte
tic()
preds <-
predict(lastfit1, new_data = germeval_test)
toc()10.773 sec elapsedd_test <-
germeval_test |>
bind_cols(preds) |>
mutate(c1 = as.factor(c1))my_metrics <- metric_set(accuracy, f_meas)
my_metrics(d_test,
truth = c1,
estimate = .pred_class)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.689
2 f_meas binary 0.196Fazit
wikipedia2vec ist für die deutsche Sprache vorgekocht. Das macht Sinn für einen deutschsprachigen Corpus.
Das Modell braucht doch ganz schön viel Rechenzeit.
Achtung: Mit dem Parameter save_pred = TRUE wird der Workflow größer als 3 GB.
Categories:
- textmining
- datawrangling
- germeval
- prediction
- tidymodels
- string