{kind=link}
#install.packages("palmerpenguins")
library(palmerpenguins)
data("penguins")
d <- penguins penguins-vis-bodymass2
vis
Aufgabe
Im Datensatz palmerpenguins: Ist der Zusammenhang zwischen Körpergewicht und Schnabelhöhe (bill depth) (vgl. Schemazeichnung hier) größer, wenn man den Zusammenhang getrennt für jede Spezies betrachtet?
Beantworten Sie diese Frage mit Hilfe einer Visualisierung!
Sie können den Datensatz so beziehen:
Oder so:
d <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/palmerpenguins/penguins.csv")Ein Codebook finden Sie hier.
Hinweise:
- Orientieren Sie sich im Übrigen an den allgemeinen Hinweisen des Datenwerks.
- Nutzen Sie das R-Paket
ggpubrzur Visualisierung. Dort finden Sie einen Befehl namensggscatter(datensatz, x-variable, y_variable, facet_by), mit dem Sie Streudiagramme aufgeteilt nach (“facettiert nach”) einer (nominal skalierten) Gruppierungsvariablen erstellen können.
Lösung
library(tidyverse)
library(ggpubr)d <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/palmerpenguins/penguins.csv")d |>
ggscatter(x = "bill_depth_mm", y = "body_mass_g", facet.by = "species")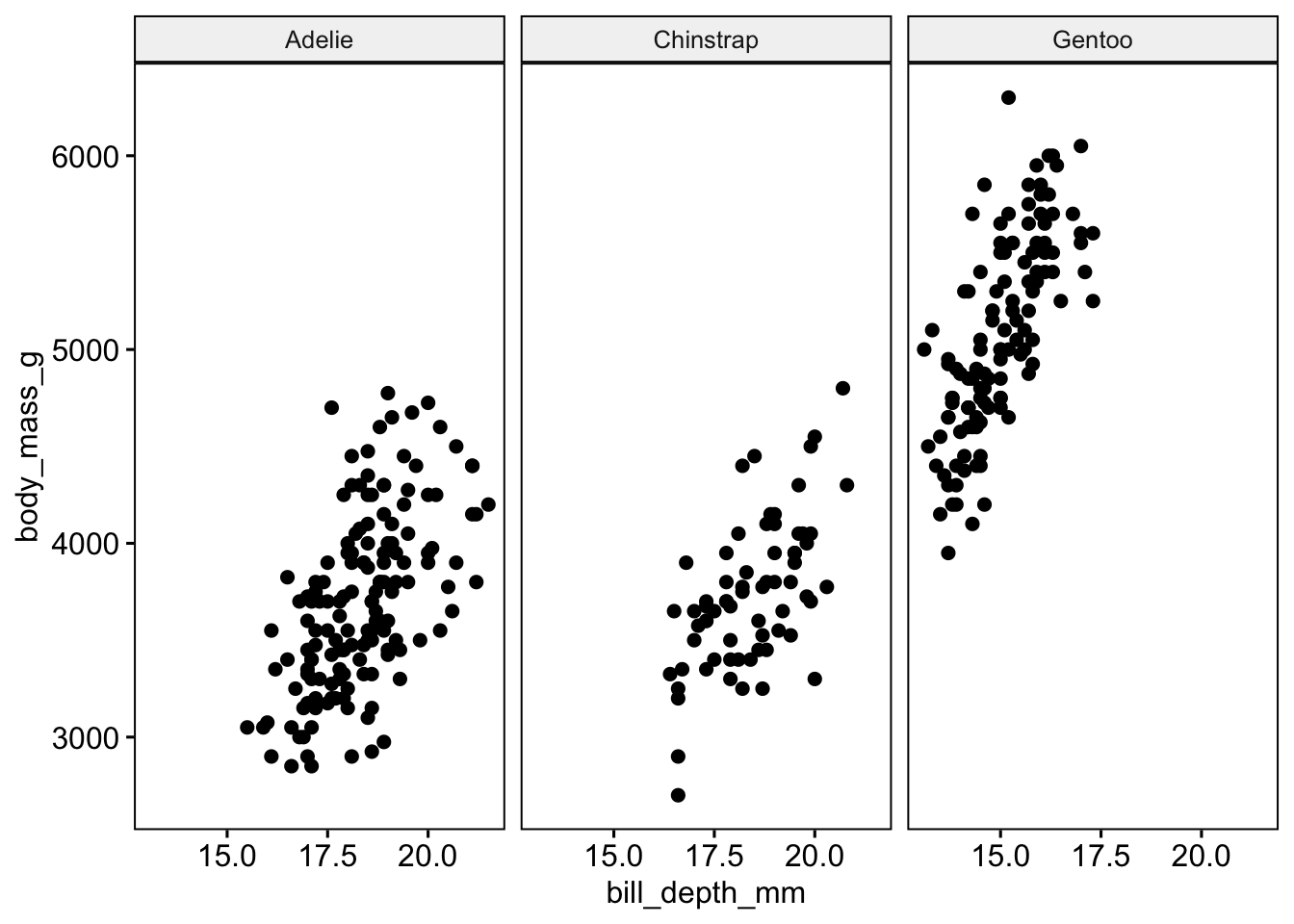
Und jetzt erstellen wir das Streudiagramm ohne Aufteilung in die Gruppen von species:
ggscatter(d, x = "bill_depth_mm", y = "body_mass_g")
Wie man sieht, tritt der Zusammenhang klarer hervor, wenn man die Daten in die von species definierten Gruppen aufteilt.