Importieren Sie das Grundatzprogramm der Partei AfD (in der aktuellsten Version). Tokenisieren Sie nach Sätzen. Dann entfernen Sie alle Zahlen. Dann zählen Sie die Anzahl der Wörter pro Satz und berichten gängige deskriptive Statistiken dazu.
Solution
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Text aus PDF-Dateien kann man mit dem Paket pdftools einlesen:
Dann erstellen wir eine Tidy-Version und tokenisieren nach Sätzen:
library(tidytext)d2 <- d %>%unnest_sentences(output = word, input = text)head(d2)
# A tibble: 6 × 1
word
<chr>
1 programm für deutschland.
2 das grundsatzprogramm der alternative für deutschland.
3 2 programm für deutschland | inhalt präambel …
4 familien stärken 43 und parteiferne rechnungshöfe …
5 3 programm für deutschland | inhalt 7 | kultur, sprache und identit…
6 förder- und 10.10.3 deutsche literatur im inland digi…
[1] "weniger subventionen 88 13.7 fischerei, forst und jagd: im einklang mit der natur 88 13.8 flächenkonkurrenz: nicht zu lasten der land- und forstwirtschaft 88"
d3$word[10]
[1] "weniger subventionen . fischerei, forst und jagd: im einklang mit der natur . flächenkonkurrenz: nicht zu lasten der land- und forstwirtschaft "
Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly.
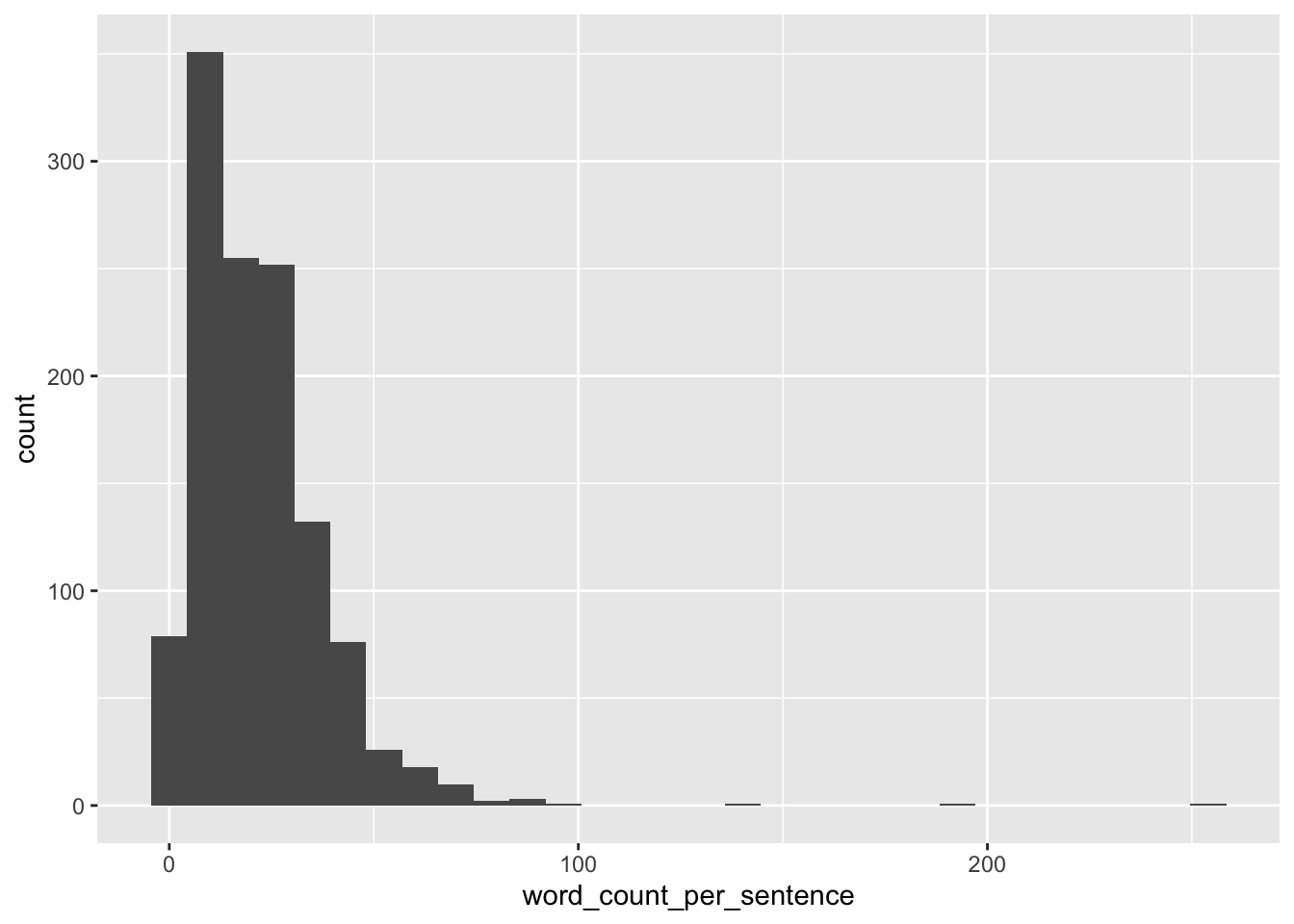
---extype: stringexsolution: NAexname: purrr-map03expoints: 1categories:- R- map- tidyversedate: '2022-10-24'slug: purrr-map03title: purrr-map03---# ExerciseImportieren Sie das Grundatzprogramm der Partei AfD (in der aktuellsten Version). Tokenisieren Sie nach Sätzen. Dann entfernen Sie alle Zahlen.Dann zählen Sie die Anzahl der Wörter pro Satz und berichten gängige deskriptive Statistiken dazu.</br></br></br></br></br></br></br></br></br></br># Solution```{r}library(tidyverse)```Text aus PDF-Dateien kann man mit dem Paket [`pdftools`](https://docs.ropensci.org/pdftools/) einlesen:```{r}library(pdftools)d_path <-"~/Literatur/_Div/Politik/afd-grundsatzprogramm-2022.pdf"d <-tibble(text =pdf_text(d_path))```Dann erstellen wir eine Tidy-Version und tokenisieren nach Sätzen:```{r}library(tidytext)d2 <- d %>%unnest_sentences(output = word, input = text)head(d2)```Dann entfernen wir die Zahlen:```{r}d3 <- d2 %>%mutate(word =str_remove_all(word, pattern ="[:digit:]+"))```Prüfen wir, ob es geklappt hat:```{r}d2$word[10]d3$word[10]```Ok.Dann zählen wir die Wörter pro Satz:```{r}d4 <- d3 %>%summarise(word_count_per_sentence =str_count(word, "\\w+"))head(d4)```Visualisierung:```{r}d4 %>%ggplot(aes(x = word_count_per_sentence)) +geom_histogram()``````{r}library(easystats)describe_distribution(d4)```---Categories: - R- map- tidyverse